𝐔𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐢𝐧𝐠 𝐰𝐢𝐭𝐡 𝐋𝐚𝐫𝐠𝐞 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥 𝐢𝐧 𝐑𝐨𝐛𝐨𝐭-𝐚𝐬𝐬𝐢𝐬𝐭𝐞𝐝 𝐒𝐮𝐫𝐠𝐞𝐫𝐲!
Thrilled to share our latest work, 𝐒𝐮𝐫𝐠𝐕𝐢𝐝𝐋𝐌, the first video-language model specifically designed to address both full and fine-grained surgical video comprehension.
Surgical scene understanding is critical for training and robotic decision-making. While current Multimodal Large Language Models (MLLMs) excel at image analysis, they often overlook the fine-grained temporal reasoning required to capture detailed task execution and specific procedural processes within a surgery. This motivated us to bridge the gap between global video understanding and micro-action analysis.
🧠✨ What we developed:
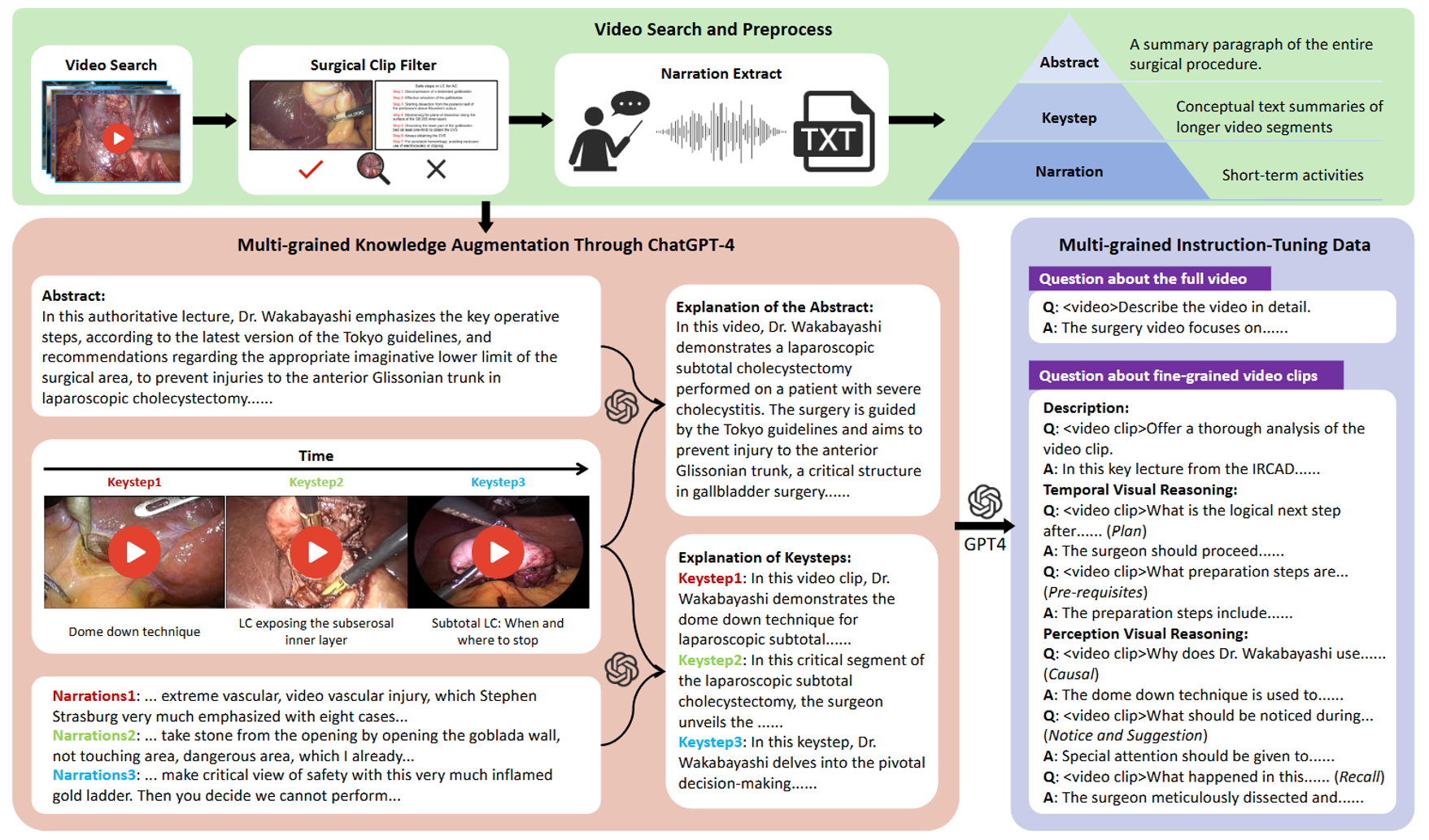
A novel framework and resource for surgical video reasoning that includes:
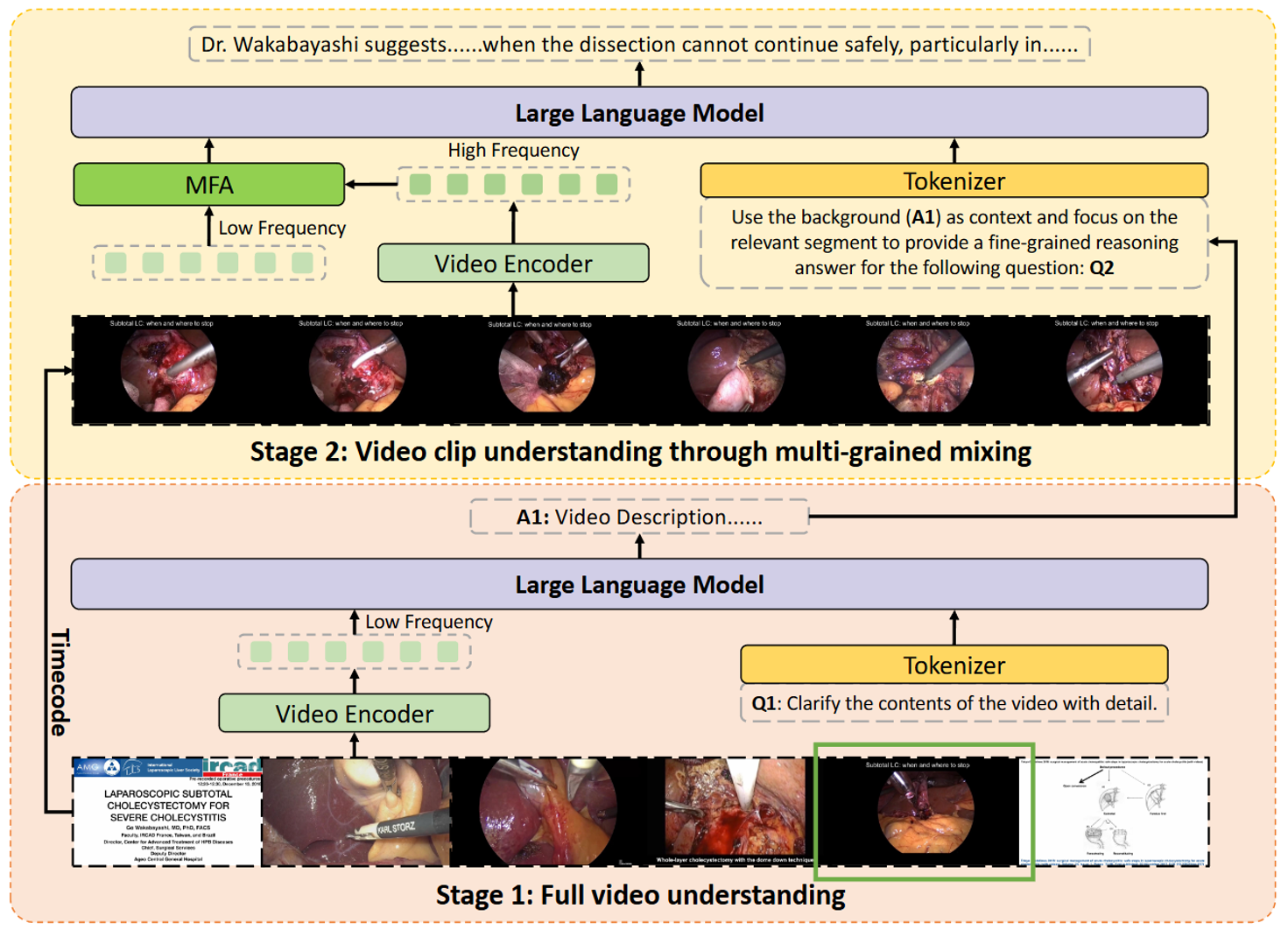
🔹 𝐓𝐰𝐨-𝐬𝐭𝐚𝐠𝐞 𝐒𝐭𝐚𝐠𝐞𝐅𝐨𝐜𝐮𝐬 𝐦𝐞𝐜𝐡𝐚𝐧𝐢𝐬𝐦: The first stage extracts global procedural context, while the second stage performs high-frequency local analysis for fine-grained task execution.
🔹 𝐌𝐮𝐥𝐭𝐢-𝐟𝐫𝐞𝐪𝐮𝐞𝐧𝐜𝐲 𝐅𝐮𝐬𝐢𝐨𝐧 𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 (𝐌𝐅𝐀): Effectively integrates low-frequency global features with high-frequency local details to ensure comprehensive scene perception.
🔹 𝐒𝐕𝐔-𝟑𝟏𝐊 𝐃𝐚𝐭𝐚𝐬𝐞𝐭: We constructed a large-scale dataset with over 31,000 video-instruction pairs, featuring hierarchical knowledge representation for enhanced visual reasoning.
🎯 Key Results:
✅ SurgVidLM significantly outperforms existing models (like Qwen2-VL) in multi-grained surgical video understanding tasks.
✅ Capable of inferring anatomical landmarks (e.g., Denonvilliers’ fascia) and providing clinical motivation, moving beyond simple visual description.
✅ Demonstrated strong performance on unseen surgical tasks, proving the robustness of our hierarchical training approach.
💡 Why it matters:
This work shows that by combining global context with localized high-frequency focus, we can significantly reduce “hallucinations” in surgical AI. It provides a pathway toward more intelligent, context-aware surgical assistants that can understand not just what is happening, but how and why specific steps are performed.
🌱 What’s next?
We are exploring how to extend this multi-grained understanding to real-time intraoperative guidance and integrating it with physical robotic control for autonomous sub-tasks.